Sliding window or attention mechanism ?
Idea of YOLO Detector
Classic object detection task normally has two steps, which are classify the content of region of interests (ROI) by e.g. CNN, and locate the ROI by e.g. “scanning with sliding window”.
Yolo uses a reasonable strong spatial constrains to merge these two steps into one step, and process the original image only once (input image to NN once), which literally means “You Only Look Once” (YOLO).
For the short explanation, Yolo divides the image into $S \times S$ grids, and suppose each cell of the grid take responsibility for the detection of objectness and classification of objects.
And the most amazing fact is, under this architecture with end-to-end training, the detection problem is converted as a regression problem.
For example, each attention cell is capable to locate and identify an arbitrary size object directly from the whole image, if the center point of object is in the corresponding cell.
By using this attention grid architecture, the inference process can be very efficient, because “You Only Look Once”.
The biggest advantage of Yolo is, that Yolo is really fast for inference.
In my experiment, Yolo3-tiny can work at 30 FPS on a normal Laptop (GeForce 930MX), which is critical for integration on a real car, due to limited computational resources.
One obviously shortage of Yolo is, due to the limited resolution of attention grid, Yolo is not good at detecting swarm objects, such as detecting bird swarm or counting crowded people. But for detection on the street, Yolo is the best option, which compromised with detection speed and detection performance in my recherche.
Yolo V3
In this project, firstly Yolo v3 was implemented (forked from Github Repo) and tested.
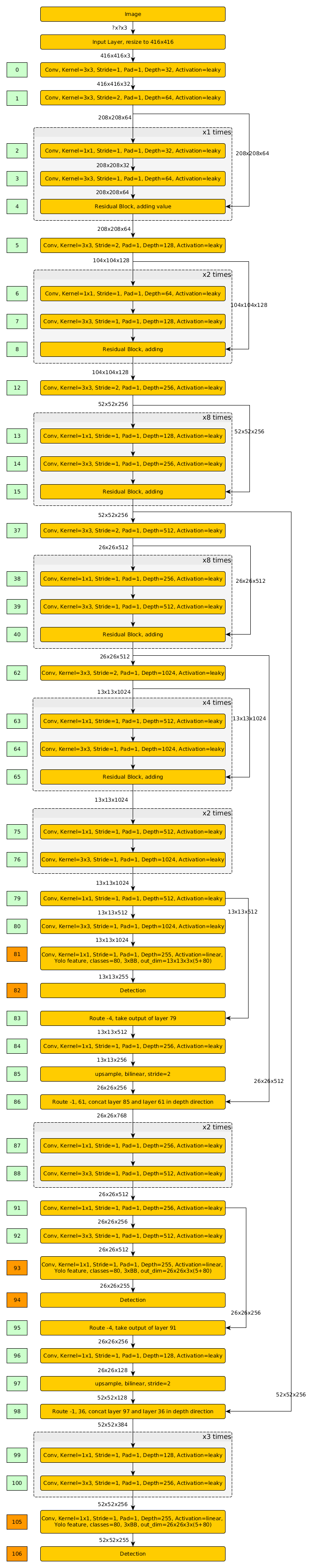
The implemented network has architecture as following Fig.3.